









 導(dǎo)航分類
導(dǎo)航分類分支機(jī)構(gòu)動(dòng)態(tài)
分支機(jī)構(gòu)動(dòng)態(tài)丨生態(tài)環(huán)境大模型應(yīng)用評(píng)估基準(zhǔn)測(cè)試(ELLE)第1賽季結(jié)果發(fā)布:12款模型誰(shuí)更“懂”環(huán)境?
近日,中國(guó)環(huán)境科學(xué)學(xué)會(huì)生態(tài)環(huán)境人工智能專委會(huì)發(fā)布生態(tài)環(huán)境大模型應(yīng)用評(píng)估基準(zhǔn)測(cè)試(Environmental large language model Evaluation, ELLE)第1賽季結(jié)果。2025年3月28日-4月3日期間,ELLE對(duì)12款主流大語(yǔ)言模型及應(yīng)用的生態(tài)環(huán)境專業(yè)能力進(jìn)行多維度測(cè)評(píng)。測(cè)評(píng)覆蓋污染治理、政策分析等核心場(chǎng)景,最終結(jié)果顯示:TianGong-Agent-2025-04-01以綜合94.3分領(lǐng)跑榜單,緊隨其后的DeepSeek-reasoner(93.8分)、ChatGPT-4o-2024-11-20(91.7分)與ChatGPT-o1-2024-12-17(91.0分)展現(xiàn)出頭部模型的技術(shù)優(yōu)勢(shì),其余模型得分集中在80-90分區(qū)間,點(diǎn)擊訪問(wèn)完整測(cè)評(píng)結(jié)果:生態(tài)環(huán)境大模型測(cè)試(ELLE)排名。

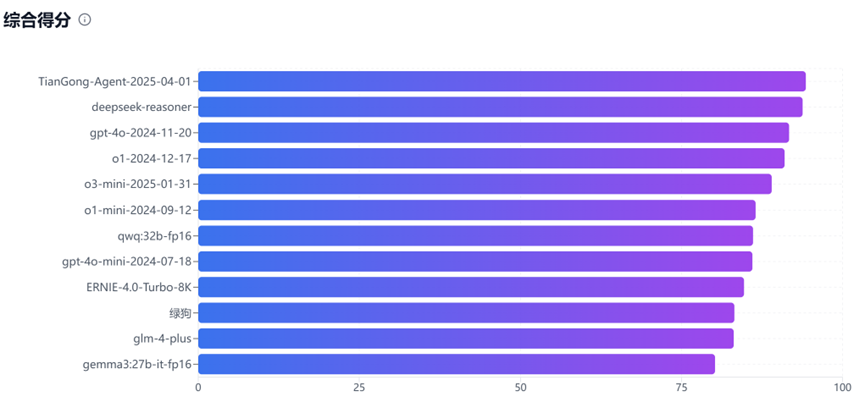
12款主流大語(yǔ)言模型ELLE綜合得分排名
本次測(cè)試包括多領(lǐng)域、多難度的生態(tài)環(huán)境專業(yè)題目,旨在考察大模型在專業(yè)計(jì)算、邏輯推理以及政策分析等多方面的綜合能力。
計(jì)算題(約35%)。涉及公式推導(dǎo)、濃度換算、工程參數(shù)計(jì)算等,如溶解氧濃度計(jì)算、污泥體積縮減以及燃料燃燒的理論空氣量計(jì)算。
邏輯推理題(約30%)。要求對(duì)污染物特征匹配、環(huán)境機(jī)制分析或治理策略選擇,如分析光化學(xué)煙霧前體匹配、水質(zhì)模型選擇等。
專業(yè)基礎(chǔ)知識(shí)題(約25%)。涉及環(huán)境現(xiàn)象解釋、技術(shù)原理或政策影響,如生物吸附劑在重金屬治理中的原理、碳泄漏機(jī)制及其國(guó)際貿(mào)易影響。
混合類型(約10%)。結(jié)合了計(jì)算與邏輯推理,典型案例如健康風(fēng)險(xiǎn)評(píng)估中日均暴露量公式的推導(dǎo)與應(yīng)用。
此次TianGong-Agent-2025-04-01智能體架構(gòu)(https://github.com/linancn/tiangong-ai-langgraph-server)憑借其智能協(xié)作框架在評(píng)測(cè)中表現(xiàn)突出。該架構(gòu)設(shè)計(jì)了一套“問(wèn)題分類→專業(yè)化處理→評(píng)估迭代”的三階段問(wèn)題解決流程。大語(yǔ)言模型首先對(duì)問(wèn)題進(jìn)行分類,隨后將問(wèn)題分配至相應(yīng)的處理模塊。在這一環(huán)節(jié),智能體針對(duì)不同類型問(wèn)題可以靈活調(diào)用相應(yīng)工具,包括自動(dòng)檢索知識(shí)庫(kù),從而更高效、準(zhǔn)確地實(shí)現(xiàn)復(fù)雜問(wèn)題的動(dòng)態(tài)處理。在得到初步答案后,智能體不會(huì)直接輸出初步結(jié)果,而是進(jìn)入評(píng)估環(huán)節(jié),通過(guò)多維度評(píng)分體系對(duì)答案質(zhì)量進(jìn)行客觀評(píng)價(jià),并提出具體改進(jìn)建議。若評(píng)分未達(dá)到預(yù)設(shè)閾值,問(wèn)題將重新進(jìn)入分類環(huán)節(jié),形成閉環(huán)優(yōu)化機(jī)制,確保最終輸出的質(zhì)量和可靠性。此外,相較于上一賽季,TianGong-Agent在部分環(huán)節(jié)使用了推理模型。通過(guò)以上策略,使TianGong-Agent能夠像專業(yè)人士一樣處理復(fù)雜問(wèn)題,識(shí)別需求、調(diào)用專業(yè)工具、評(píng)估反思并持續(xù)改進(jìn),顯著提高了問(wèn)題解決的準(zhǔn)確性,實(shí)現(xiàn)比原生大語(yǔ)言模型更優(yōu)的領(lǐng)域?qū)I(yè)性。
隨著領(lǐng)域數(shù)據(jù)的不斷補(bǔ)充,大語(yǔ)言模型及其應(yīng)用在生態(tài)環(huán)境領(lǐng)域的學(xué)科專業(yè)度、應(yīng)用廣度與解題深度方面都有望迎來(lái)進(jìn)一步的提升。我們誠(chéng)摯歡迎更多研究者與開發(fā)者參與到ELLE基準(zhǔn)測(cè)試工作中,共同推動(dòng)AI在綠色發(fā)展和生態(tài)文明建設(shè)中發(fā)揮更加積極的作用。


供稿丨中國(guó)環(huán)境科學(xué)學(xué)會(huì)生態(tài)環(huán)境人工智能專業(yè)委員會(huì)


